|
I am an incoming Ph.D. student at Carnegie Mellon University (CMU), affiliated with the Language Technologies Institute (LTI) in the School of Computer Science (SCS), and the newly founded Institute for Computer-Aided Reasoning in Mathematics (ICARM). I received my B.S. in Computer Science from California Institute of Technology (Caltech), with a minor in Robotics, advised by Prof. Steven Low and Prof. Günter Niemeyer. I'm happy to chat about research. Feel free to email me first, then book a time on my calendar. 宋沛洋 / Email / CV / / Google Scholar / GitHub / LinkedIn / X / IG / WeChat |

|
|
[Jul 2026] Our MATH-AI workshop is now calling for papers (CFP, OpenReview), reviewers (nomination form), and sponsors (DM me!). |
|
I study machine reasoning, in both formal and informal worlds: how AI systems can derive conclusions, act on them, evolve as tasks drift, and remain reliable when settings become complex. (1) Formal reasoning. In mathematics, code, and other formalizable domains, verifiability gives us a rare foundation for building dependable reasoning systems. I develop models and infrastructure [LeanDojo] [Lean Copilot] that form a bidirectional loop between formal environments and ML systems, enabling efficient human-AI collaboration in theorem proving [Human-AI Formalization]. Building on this loop, I move beyond static models toward adaptive agents that evolve with growing libraries [LeanAgent] and expanding contexts [LeanProgress]. (2) Informal reasoning. In open-ended natural-language settings, I continue to study how agents adapt [Adaptation] [Steer2Adapt] and generalize [Generalization] [Idiom]. These goals, however, become inherently harder to pursue in the absence of symbolic verifiers or reliable reward signals. To fundamentally alleviate this challenge, one way forward is to develop meaningful agent-centered evaluations that elicit and capture rich behavioral signals across diverse real-world scenarios [Interactive Evaluation] [Personality Illusion] [Psychometrics]. Then at runtime, the complementary challenge is to equip reasoning systems to identify, mitigate, and resist failures as they inevitably arise [Reasoning Failures] [A-Not-B]. Earlier, I also worked on making reasoning systems more efficient through novel architecture design [Delay Space] [DelayNet]. My long-term research goal is to build AI systems whose reasoning is as creative as human intuition and as dependable as formal logic. If we share any common interests, please feel free to reach out — I'd love to chat and/or collaborate. |
|
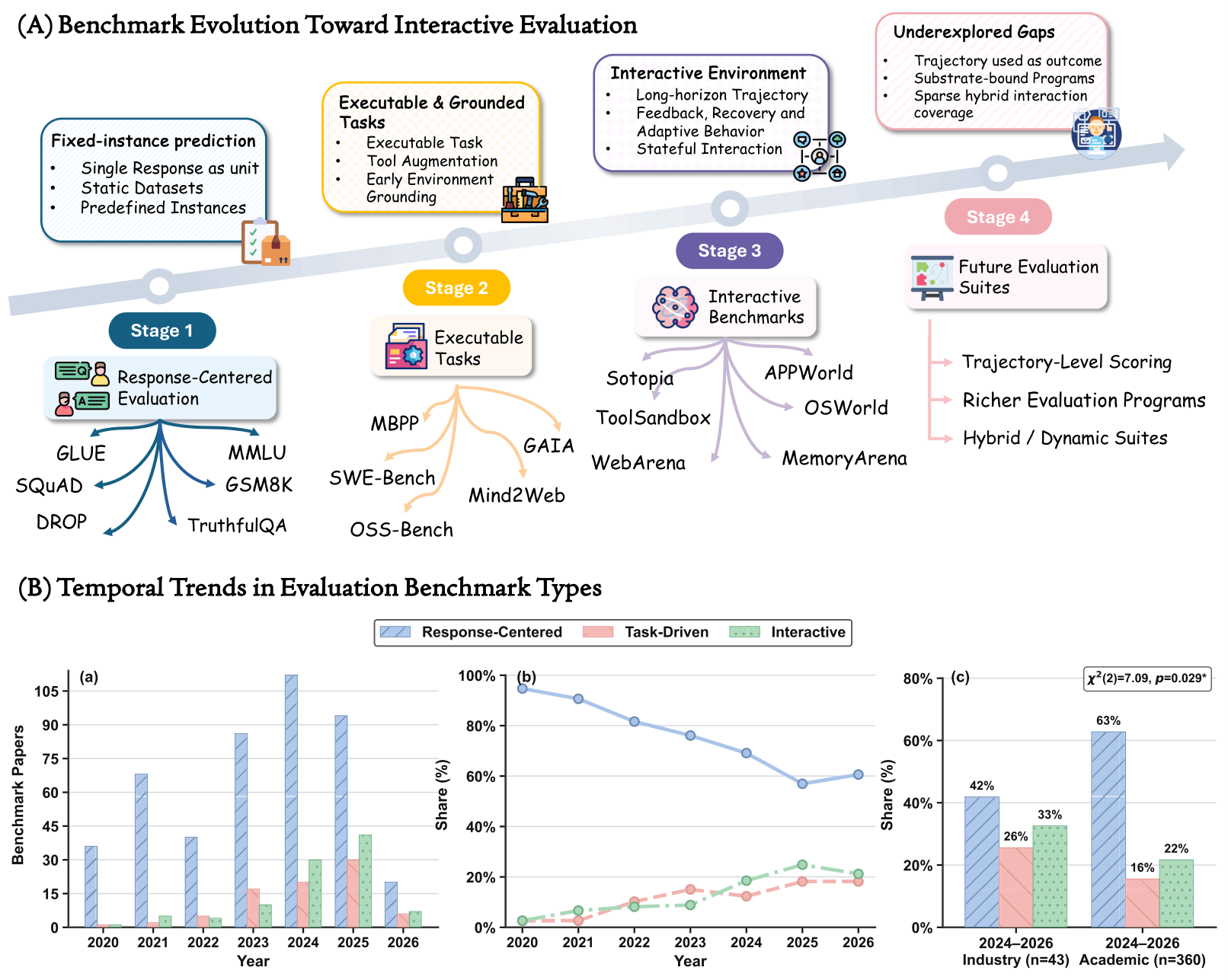
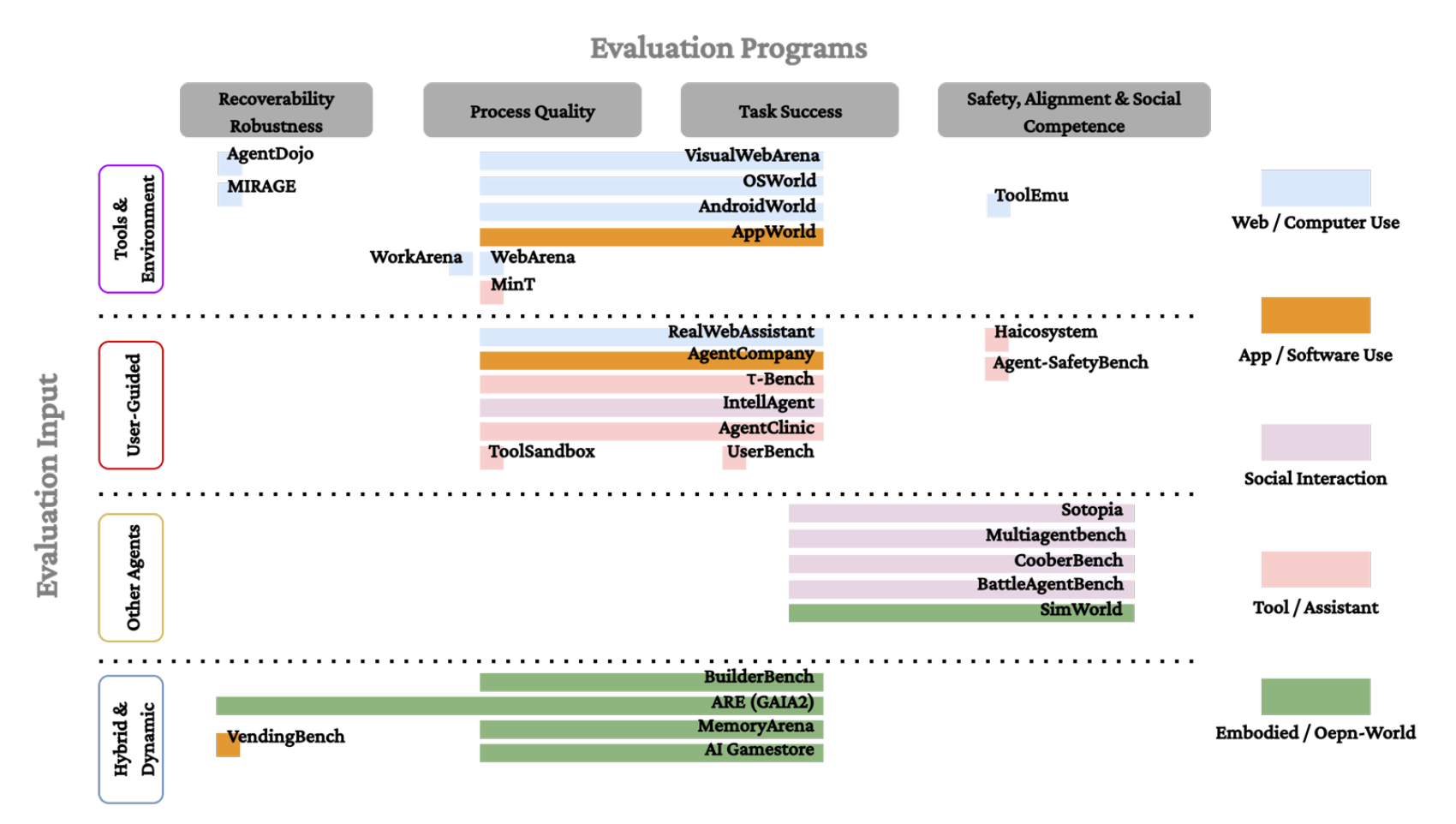
Keyang Xuan*, Peiyang Song*, Pan Lu, Pengrui Han, Wenkai Li, Zhenyu Zhang, Zexue He, Wenyue Hua, Manling Li, Jiaxuan You, Adrian Weller, Yizhong Wang†, and Jiaxin Pei† (* Equal Contribution, † Equal Advising) ICML Workshop on Combining Theory and Benchmarks (CTB), 2026 arXiv / code AI evaluation is increasingly moving beyond static responses toward systems that act through tools, environments, users, and other agents. But the field risks adding interaction faster than it develops the scientific foundations for evaluating interaction. We argue that interactive evaluation needs a design science, not just more agent benchmarks. We define interactive evaluation, propose a 2-axis taxonomy, and outline principles for designing evaluations that are interpretable, comparable, and scientifically useful. |
|
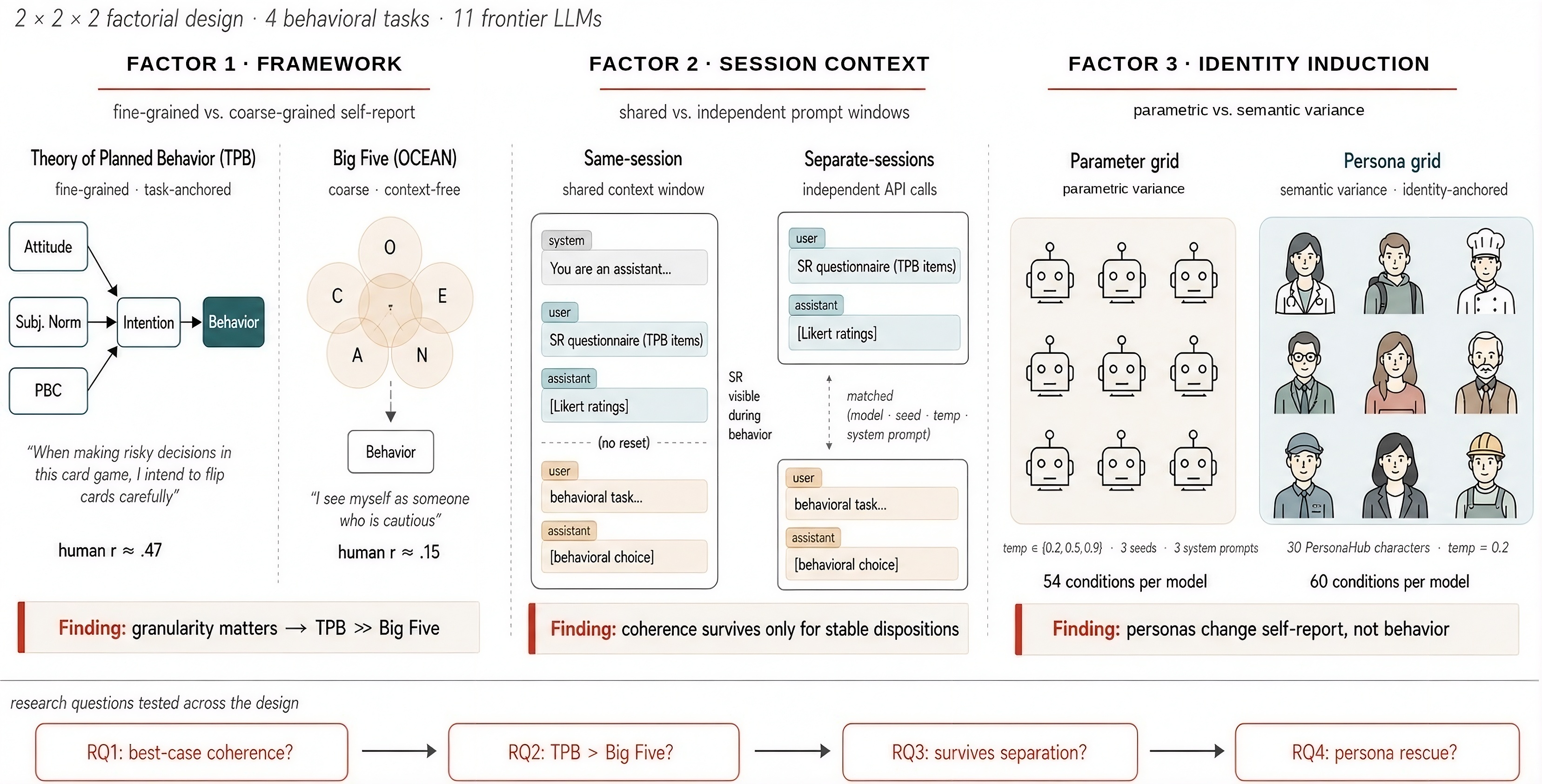
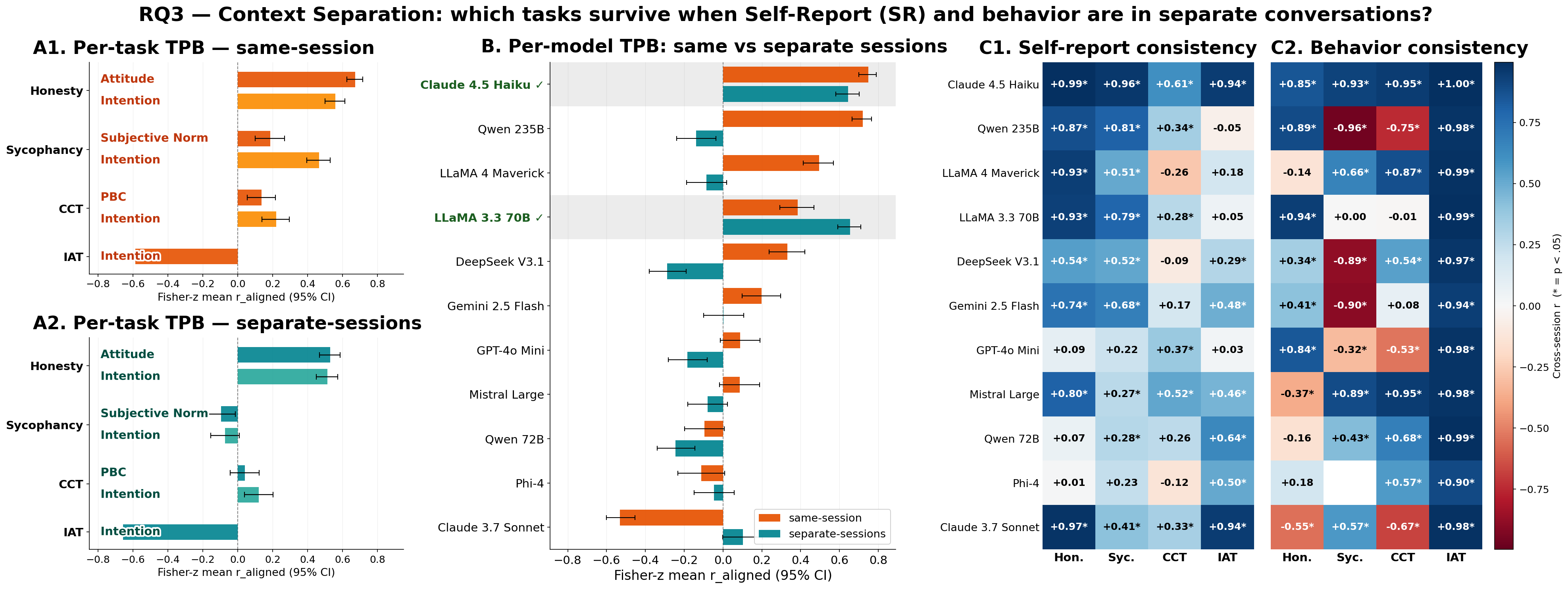
Rafal D. Kocielnik, Pengrui Han, Peiyang Song, Myrl G. Marmarelis, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez ICML Workshop on Combining Theory and Benchmarks (CTB), 2026, Best Paper Award arXiv / project / code / poster Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports reliably predict behavior. We compare broad Big 5 traits with the Theory of Planned Behavior, which targets intentions toward specific behaviors and better predicts when self-reports translate into action. |
|
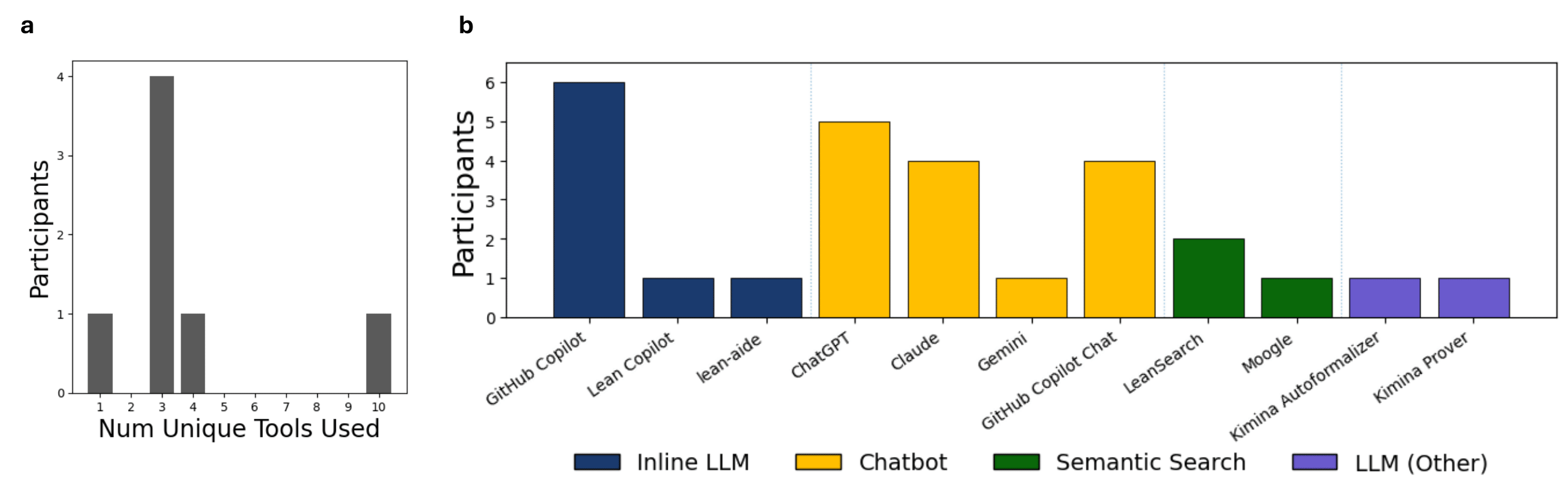
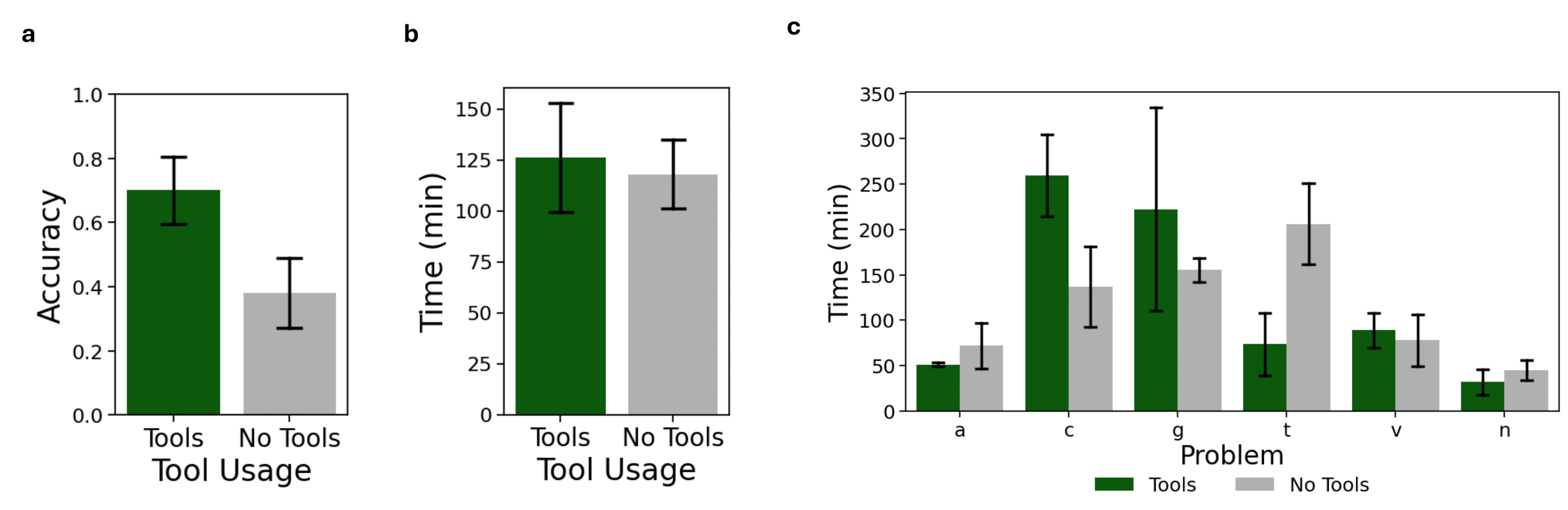
Katherine M. Collins*, Simon Frieder*, Jonas Bayer, Jacob Loader, Jeck Lim, Peiyang Song, Fabian Zasier, Lexin Zhou, Shanda Li, Shi-Zhuo Looi, Jose Hernandez-Orallo, Joshua B. Tenenbaum, Cameron Freer, Umang Bhatt, Adrian Weller, Valerie Chen†, Ilia Sucholutsky† (* Equal Contribution, † Equal Advising) NeurIPS Workshop on Mathematical Reasoning and AI (MATH-AI), 2025 arXiv / project We conduct a mixed-methods analysis into the initial impact of AI on people's formalization workflows: what people claim they want, what they see as the barriers to those visions, and how they actually use and adapt AI in practice. |
|
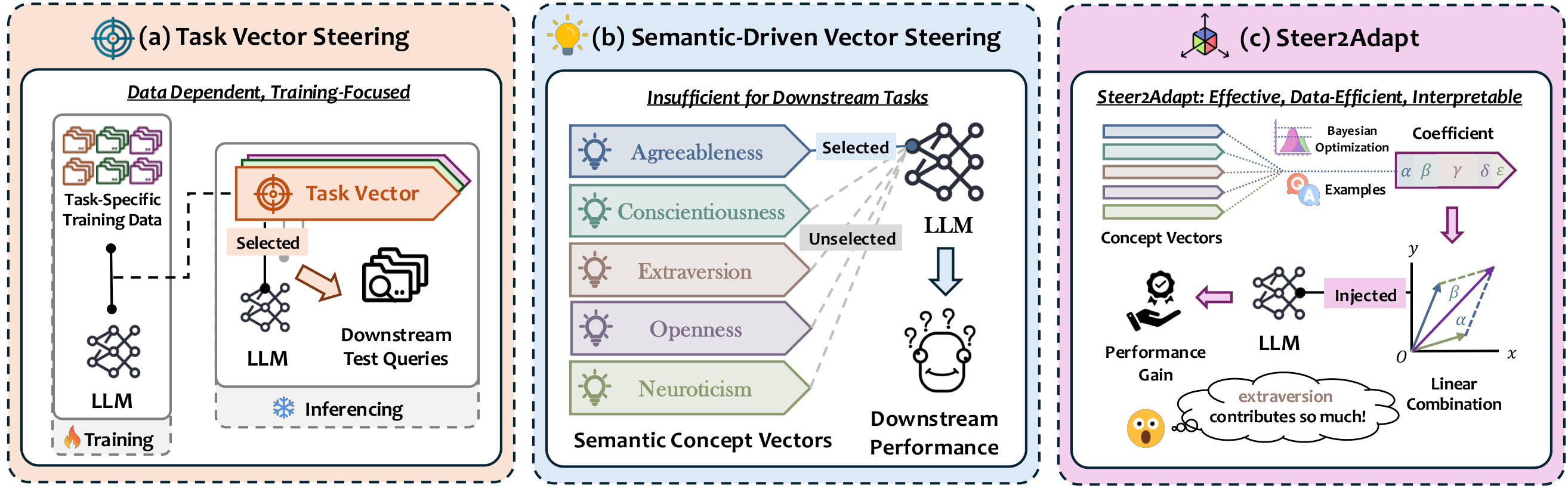
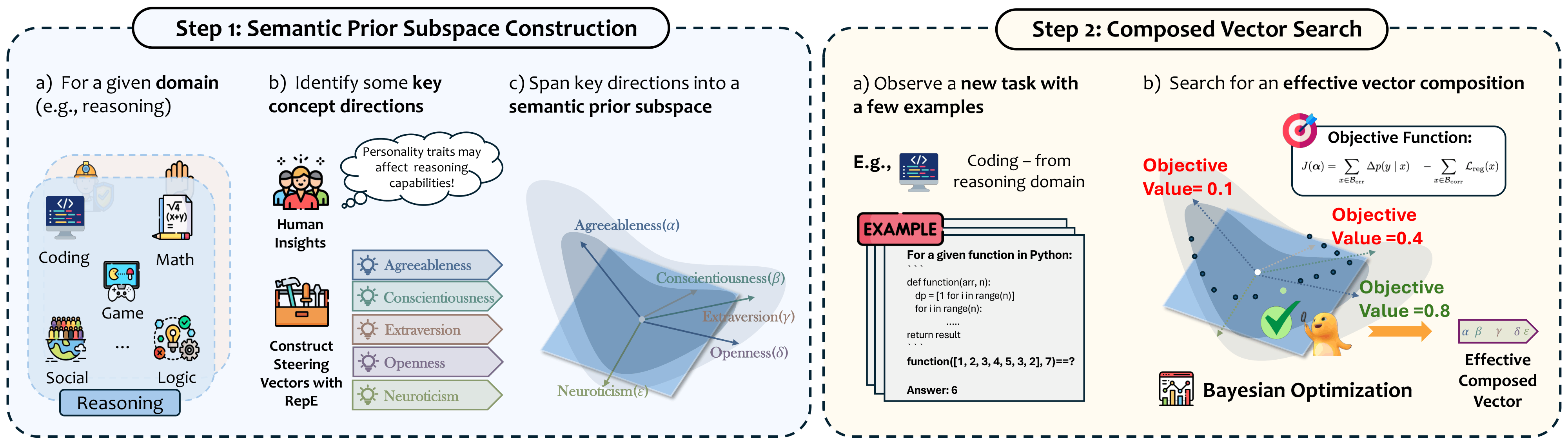
Pengrui Han*, Xueqiang Xu*, Keyang Xuan*, Peiyang Song, Siru Ouyang, Runchu Tian, Yuqing Jiang, Qian Cheng, Pengcheng Jiang, Jiashuo Sun, Junxia Cui, Ming Zhong, Ge Liu, Jiawei Han, and Jiaxuan You (* Equal Contribution) ICLR Workshop on Representational Alignment (Re-Align), 2026 arXiv Steer2Adapt adapts LLMs by composing reusable steering vectors instead of learning new task-specific directions from scratch. With only a handful of examples, it dynamically discovers combinations of semantic basis vectors for reasoning and safety tasks, yielding data-efficient, stable, and transparent inference-time adaptation. |
|
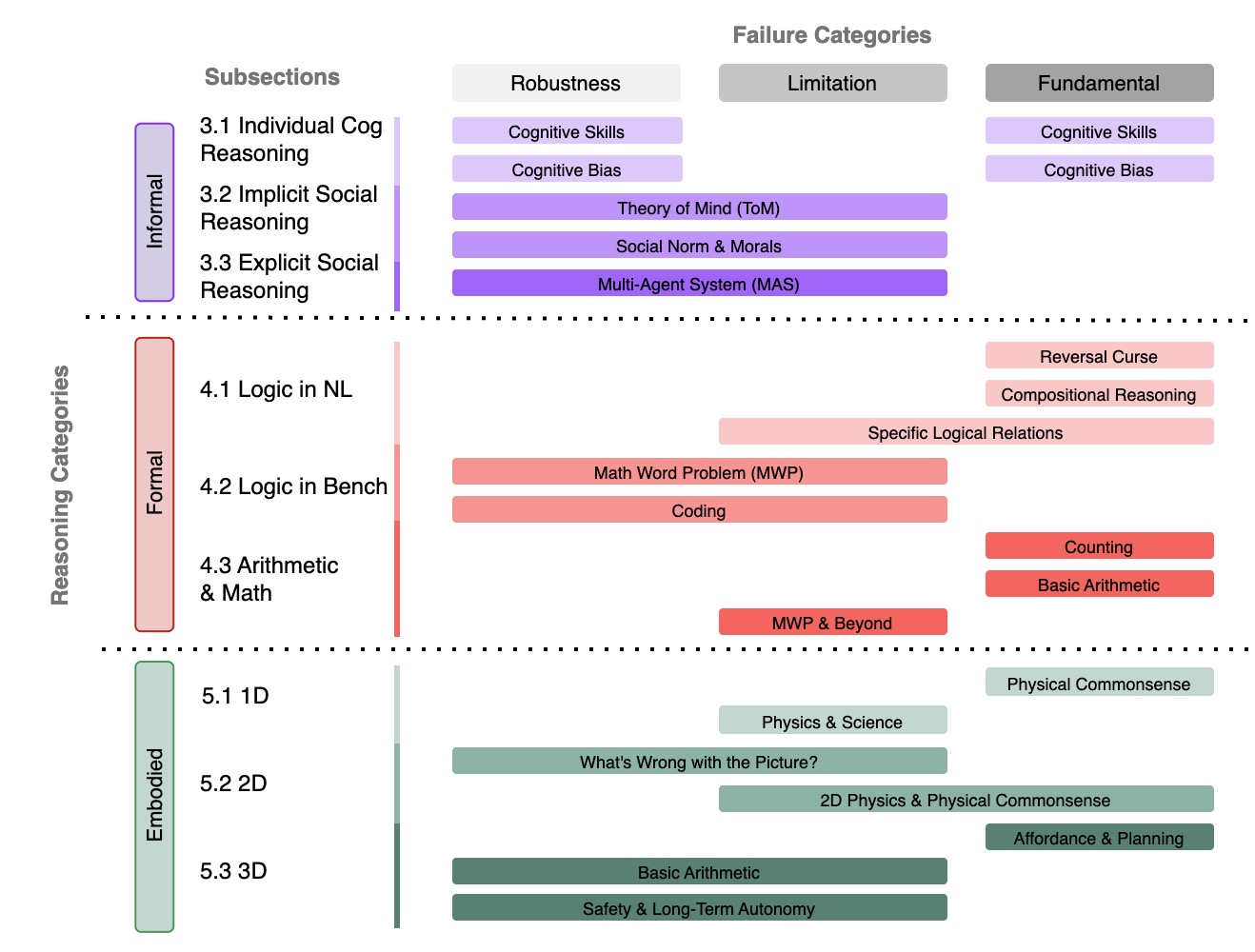
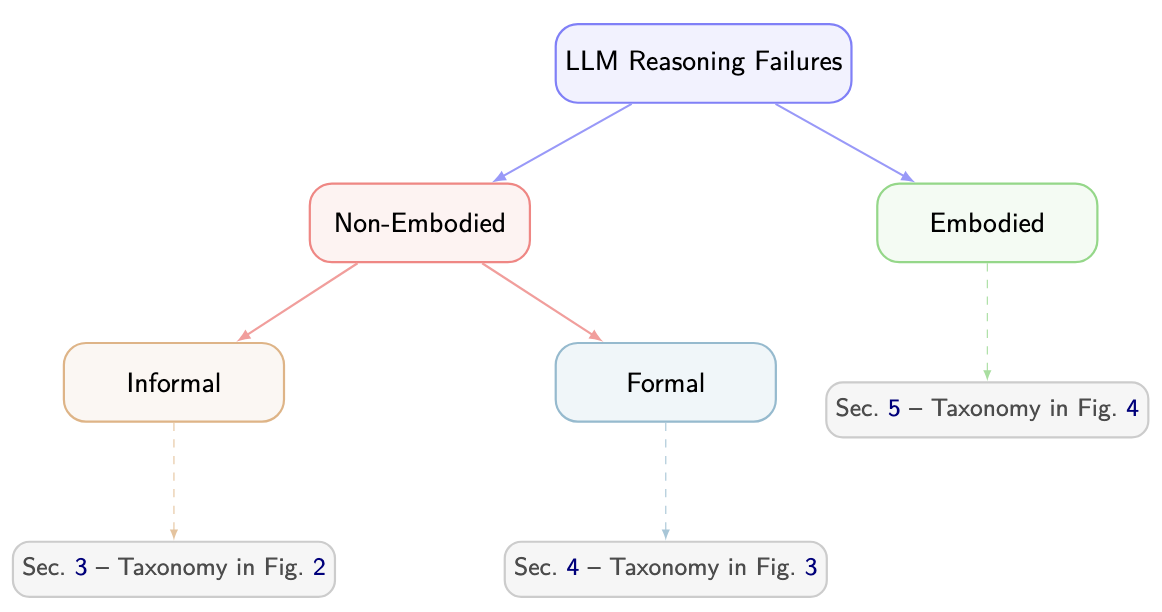
Peiyang Song*, Pengrui Han*, and Noah Goodman (* Equal Contribution) Transactions on Machine Learning Research (TMLR), 2026, Survey Certification arXiv / code / proceeding / media / talk We present the first comprehensive survey dedicated to reasoning failures in LLMs. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. |
|
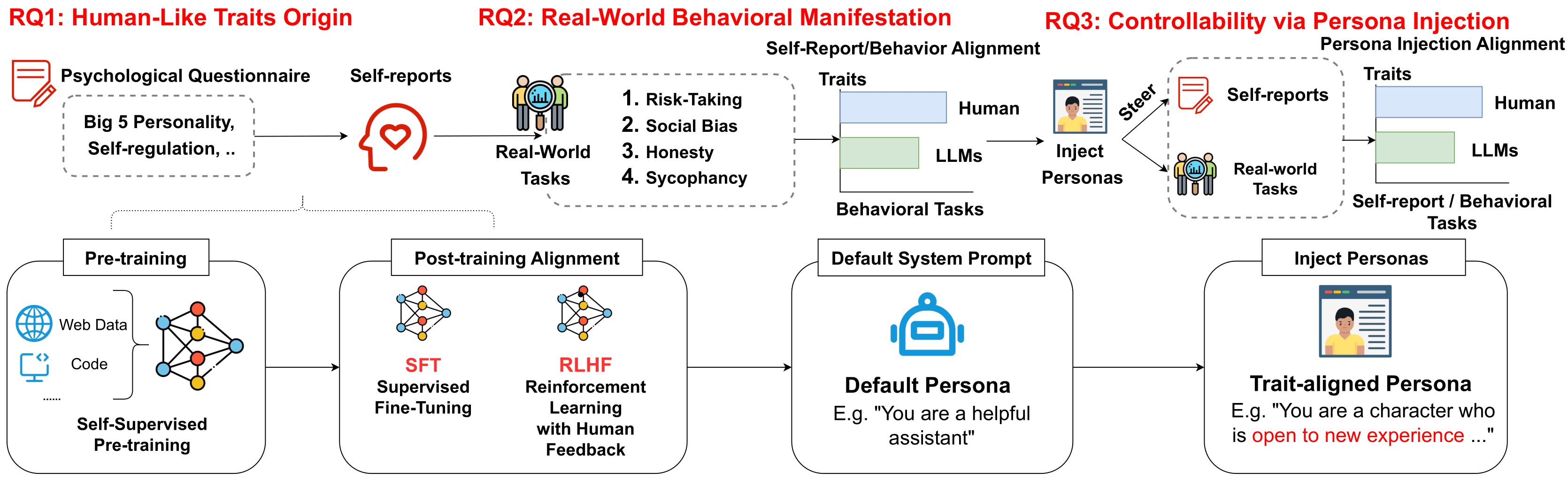
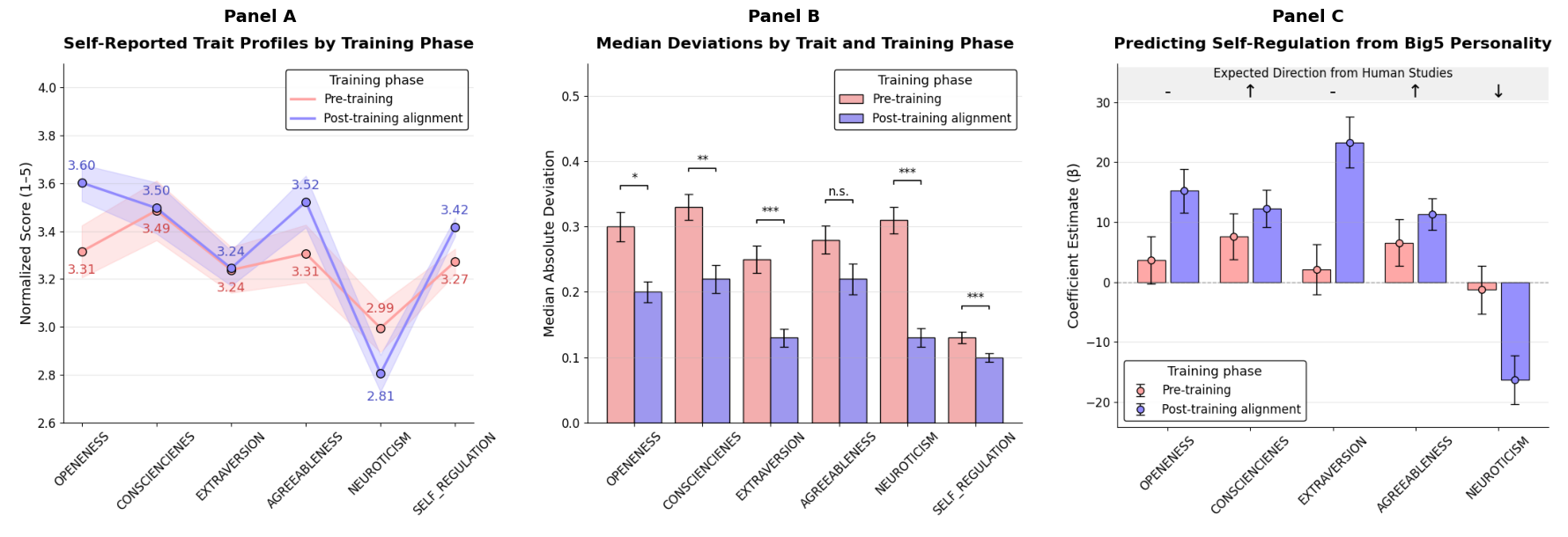
Pengrui Han*, Rafal D. Kocielnik*, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez (* Equal Contribution) International Conference on Machine Learning (ICML), 2026 Best Paper Honorable Mention @ NeurIPS LAW Workshop, 2025 arXiv / project / code / poster / media LLMs say they have personalities, but they don’t act like it. Alignment today shapes language, not behavior. This linguistic–behavioral dissociation cautions against equating coherent self-reports with cognitive depth. |
|
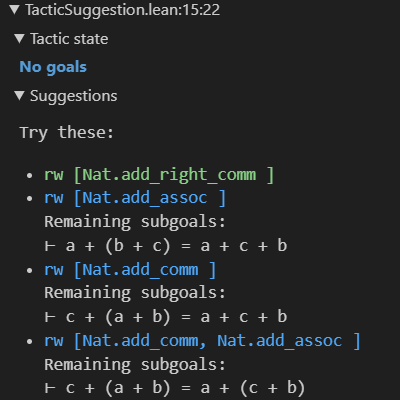
Peiyang Song, Kaiyu Yang, and Anima Anandkumar International Conference on Neuro-Symbolic Systems (NeuS), 2025 1.3k+ stars on Github, ranking 2nd (only after Mathlib4) among all Lean projects arXiv / project / code / proceeding / poster / demo / slides / tutorial / media We introduce Lean Copilot, a framework for running neural network inference directly in Lean. It enables various LLM-based proof automation tools that integrate seamlessly into the workflow of Lean users, including tools for suggesting proof steps (tactics), selecting premises, and searching for complete proofs using LLMs. |
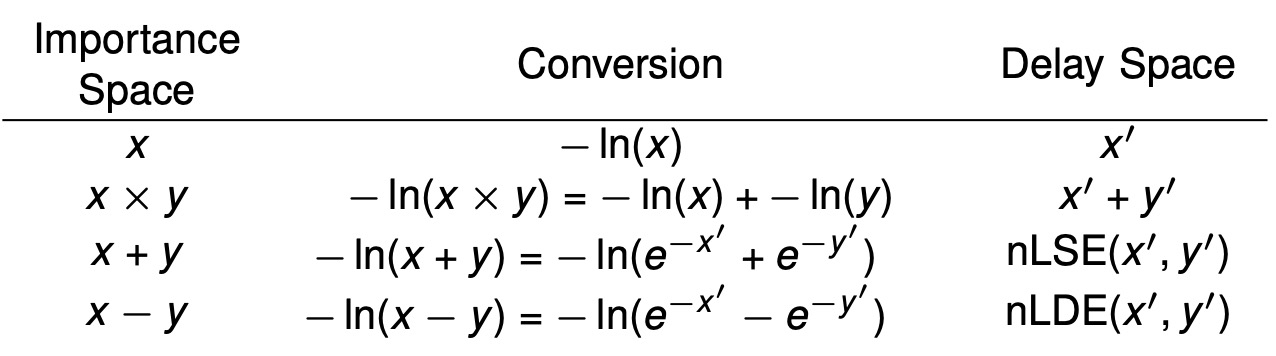
|
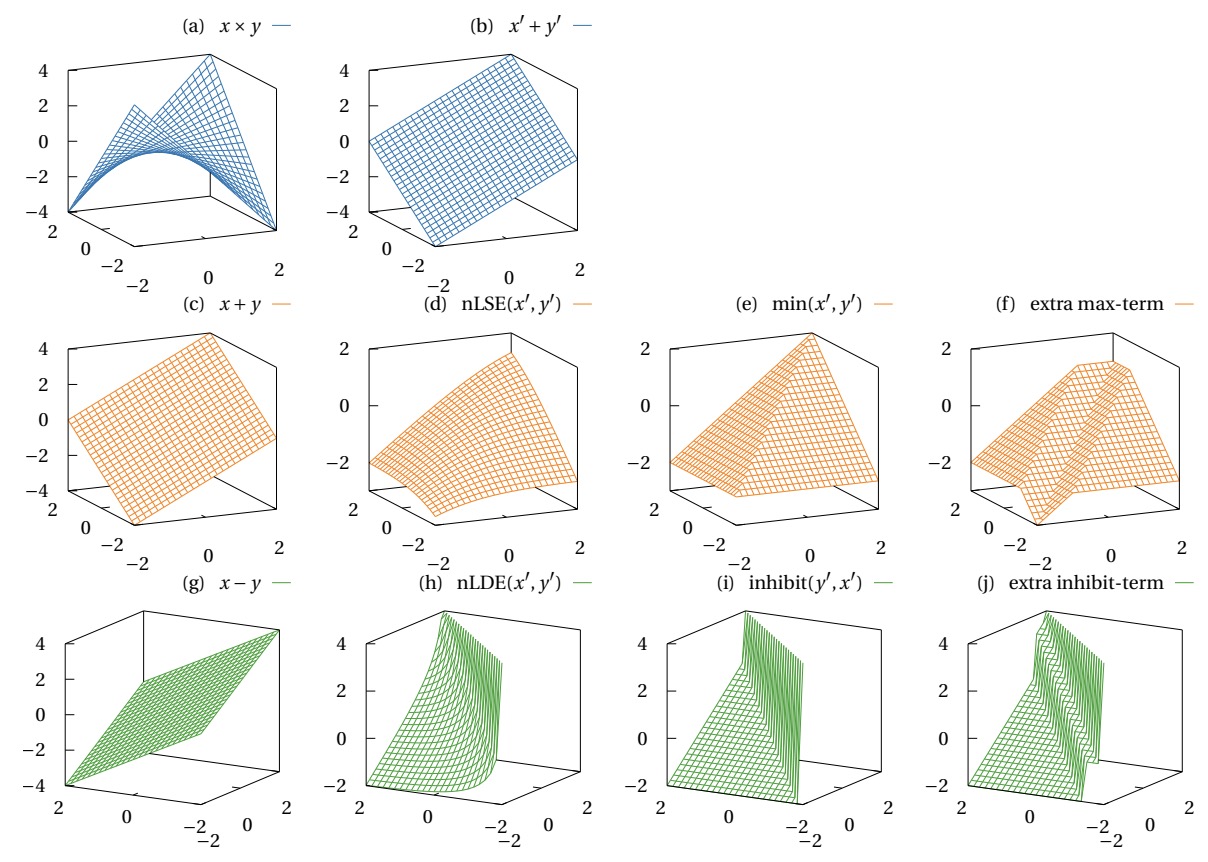
Rhys Gretsch, Peiyang Song, Advait Madhavan, Jeremy Lau, and Tim Sherwood IEEE Micro, 2025, Top Pick Award proceeding What operations can you perform efficiently when you use the “time of arrival” of a signal’s edge to represent a number? We present negative-logarithmic delay space arithmetic as a completely new approach to temporal coding. Under this approach, general purpose arithmetic is transformed to a “soft” version of the standard temporal operations in such a way that preserves all of the algebraic identities. |

|
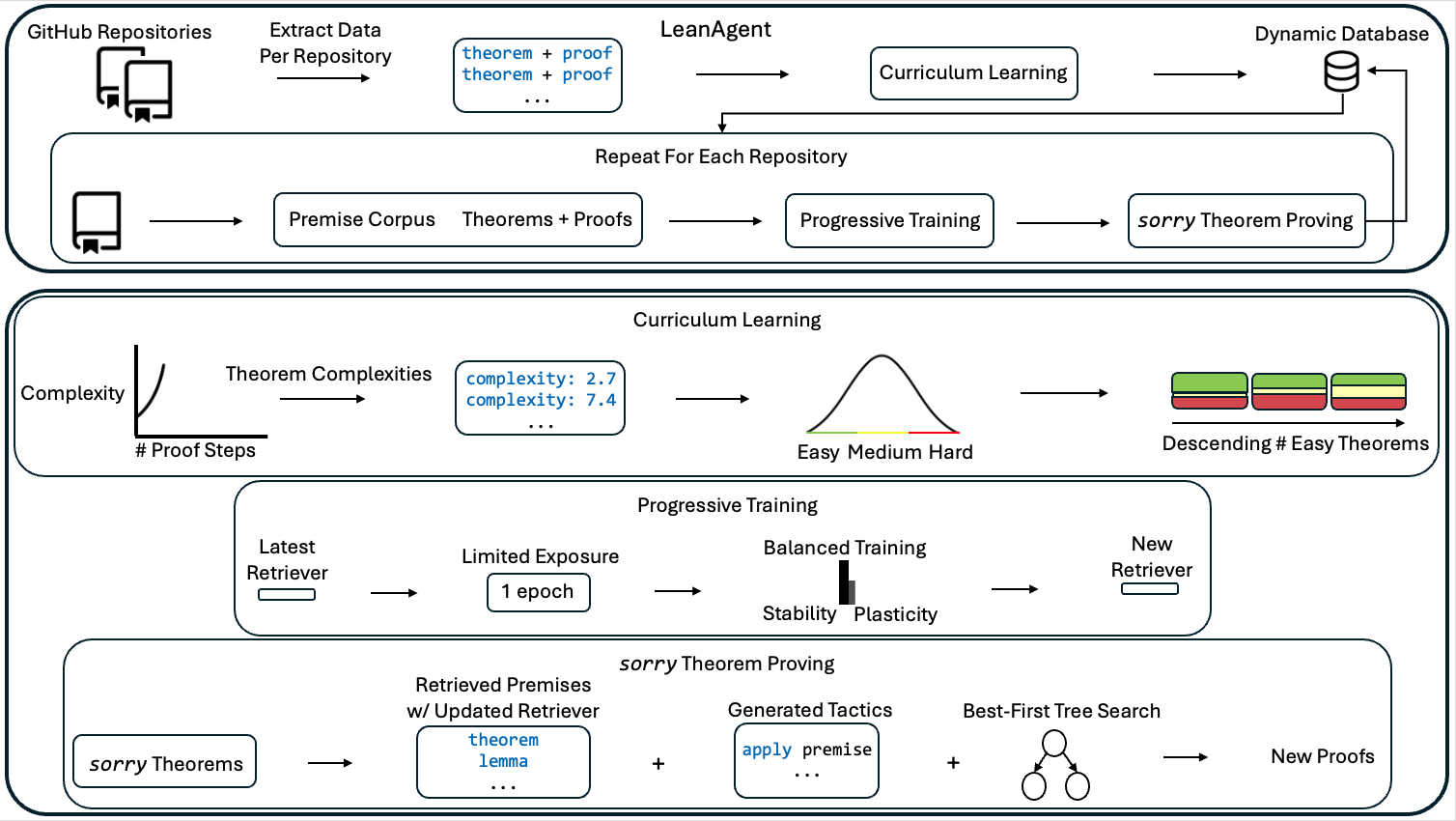
Adarsh Kumarappan*, Mo Tiwari*, Peiyang Song, Robert Joseph George, Chaowei Xiao, and Anima Anandkumar (* Equal Contribution) International Conference on Learning Representations (ICLR), 2025 arXiv / project / code / proceeding / poster / media LeanAgent continuously learns and improves on ever-expanding mathematical knowledge without forgetting what it learned before. It has a curriculum learning strategy that optimizes the learning trajectory in terms of mathematical difficulty, a dynamic database for efficient management of evolving mathematical knowledge, and progressive training to balance stability and plasticity. |
|
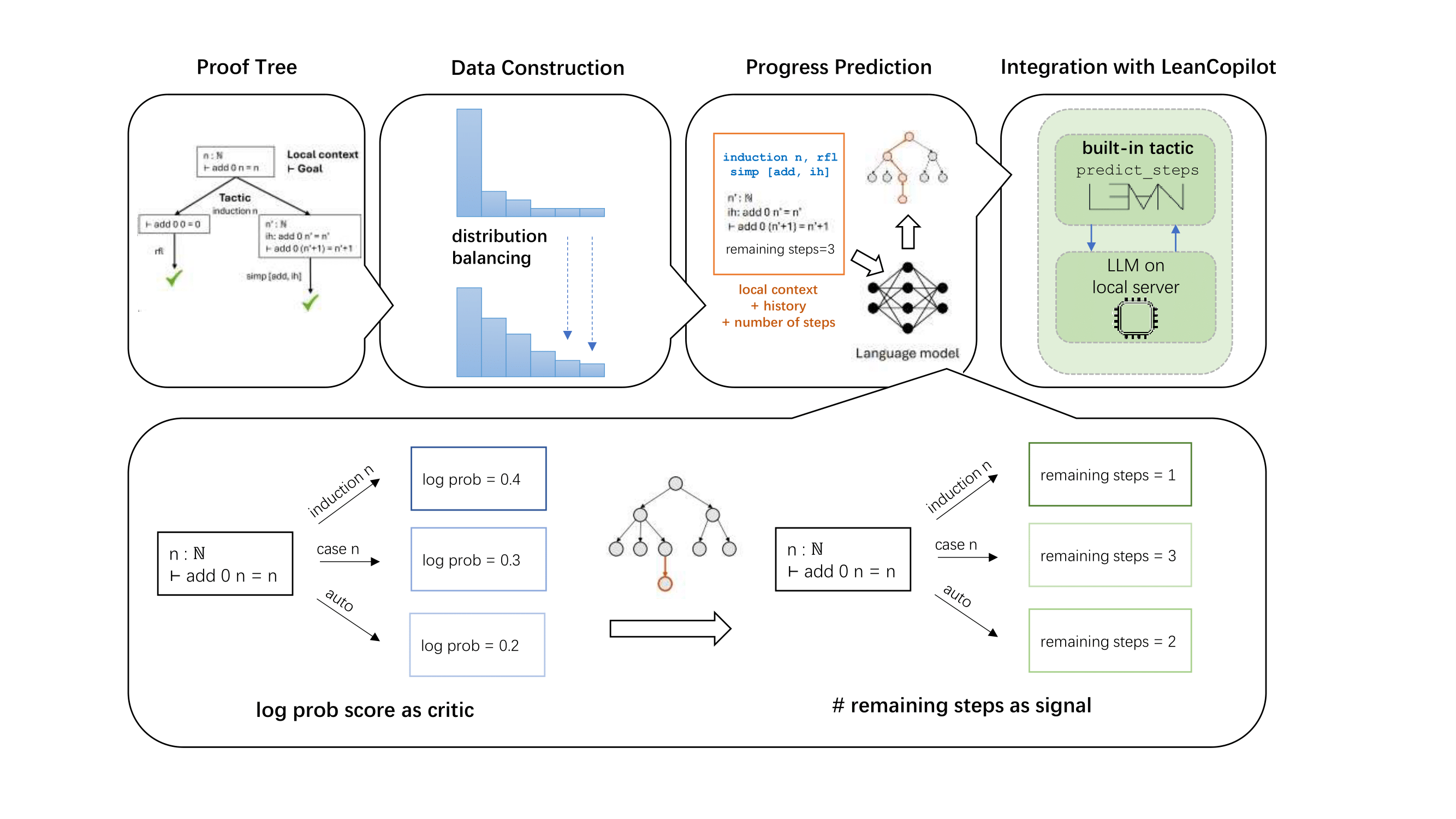
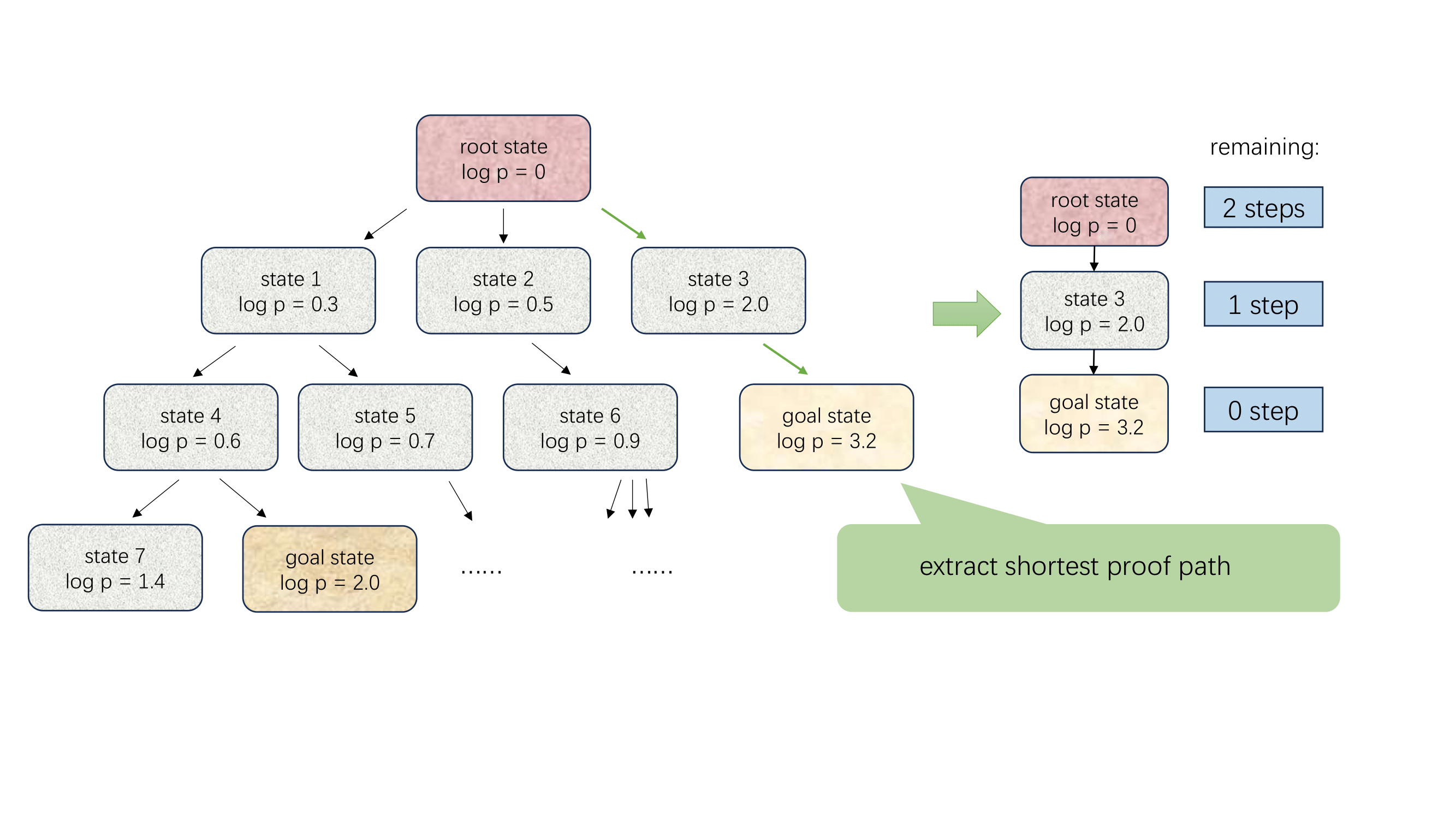
Robert Joseph George, Suozhi Huang, Peiyang Song, and Anima Anandkumar Transactions on Machine Learning Research (TMLR), 2025 arXiv / project LLMs struggling with long proofs? We present LeanProgress, which uses a novel critic model where “distance” to the goal state acts as a key signal for step prediction, boosting performance on neural theorem proving in Lean. Our method achieves 75.1% prediction accuracy, with a 3.8% gain in proof search with step prediction. |
|
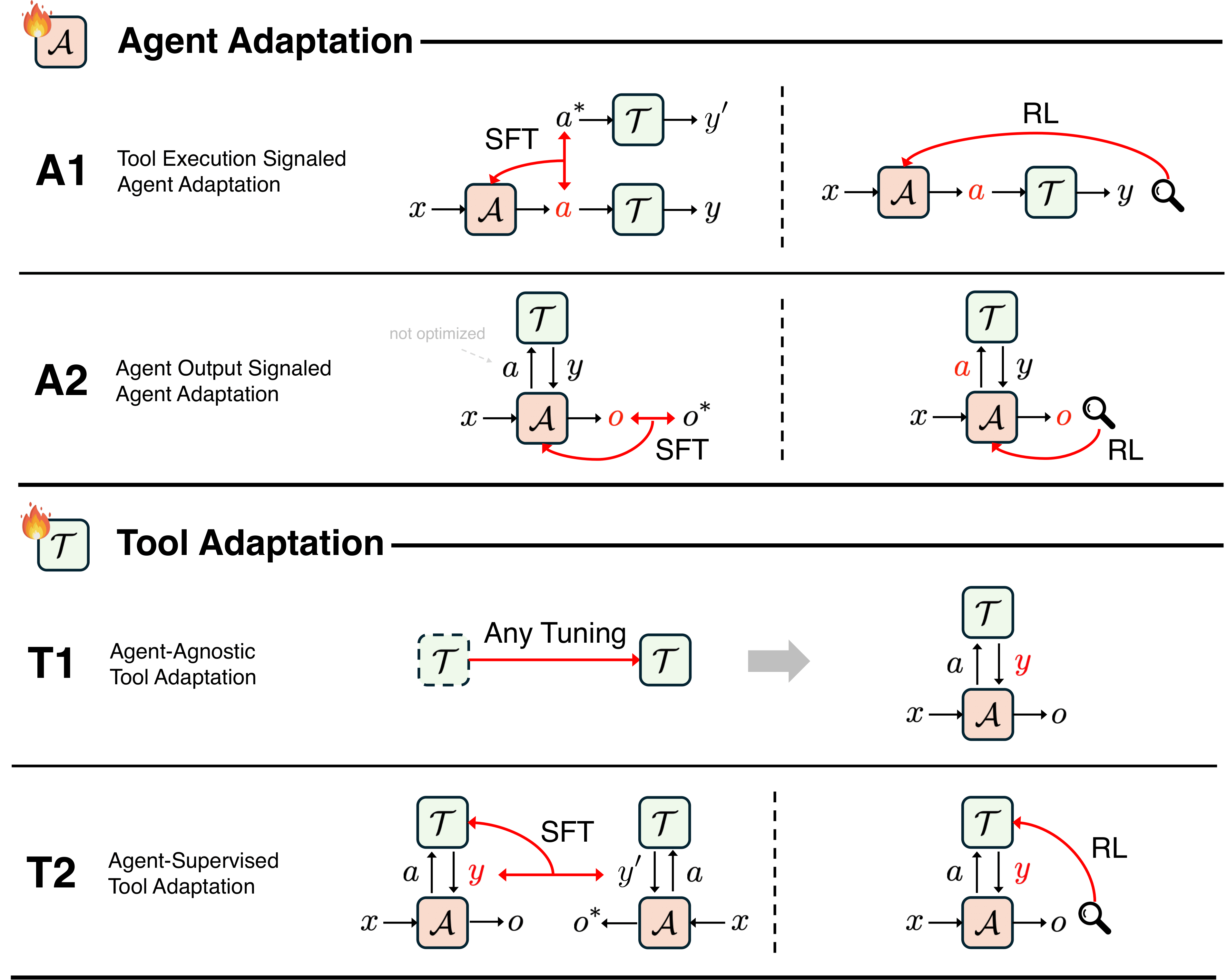
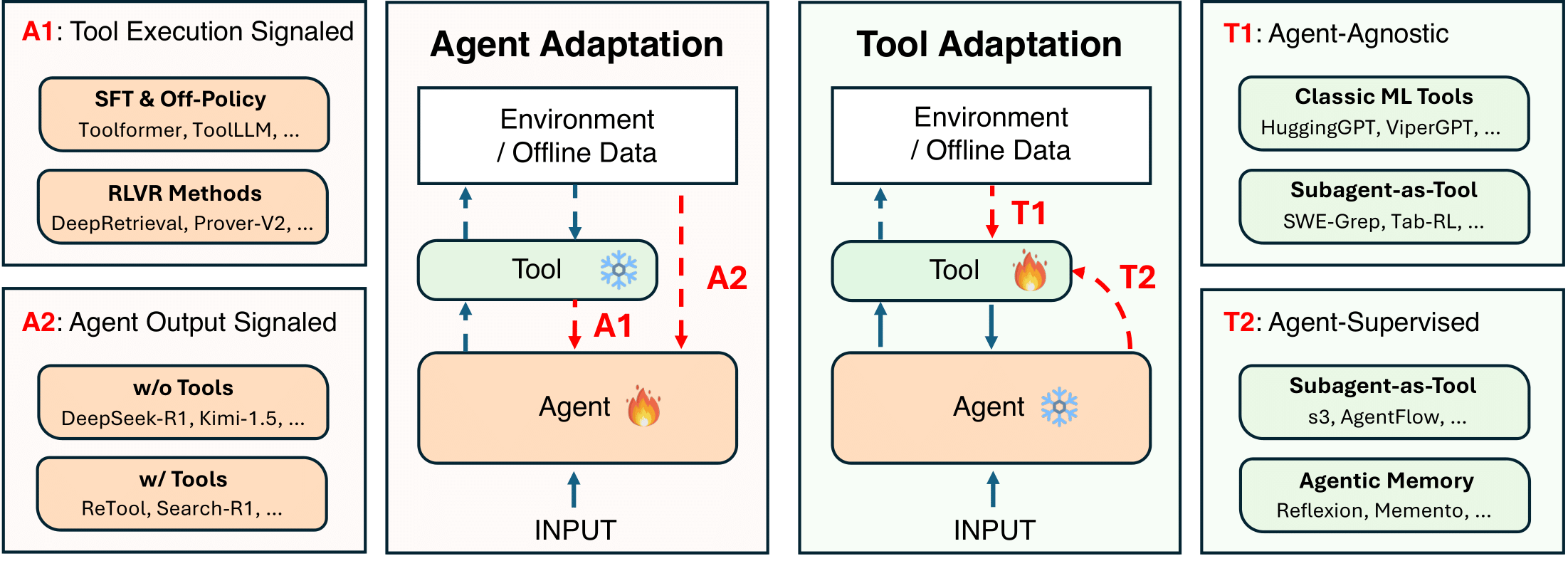
Pengcheng Jiang*, Jiacheng Lin*, Zhiyi Shi*, Zifeng Wang, Luxi He, Yichen Wu, Ming Zhong, Peiyang Song, Qizheng Zhang, Heng Wang, Xueqiang Xu, Hanwen Xu, Pengrui Han, Dylan Zhang, Jiashuo Sun, Chaoqi Yang, Kun Qian, Tian Wang, Changran Hu, Manling Li, Quanzheng Li, Hao Peng, Sheng Wang, Jingbo Shang, Chao Zhang, Jiaxuan You, Liyuan Liu, Pan Lu, Yu Zhang, Heng Ji, Yejin Choi, Dawn Song, Jimeng Sun, Jiawei Han (* Equal Contribution) Preprint, 2025 arXiv / code / media Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. |
|
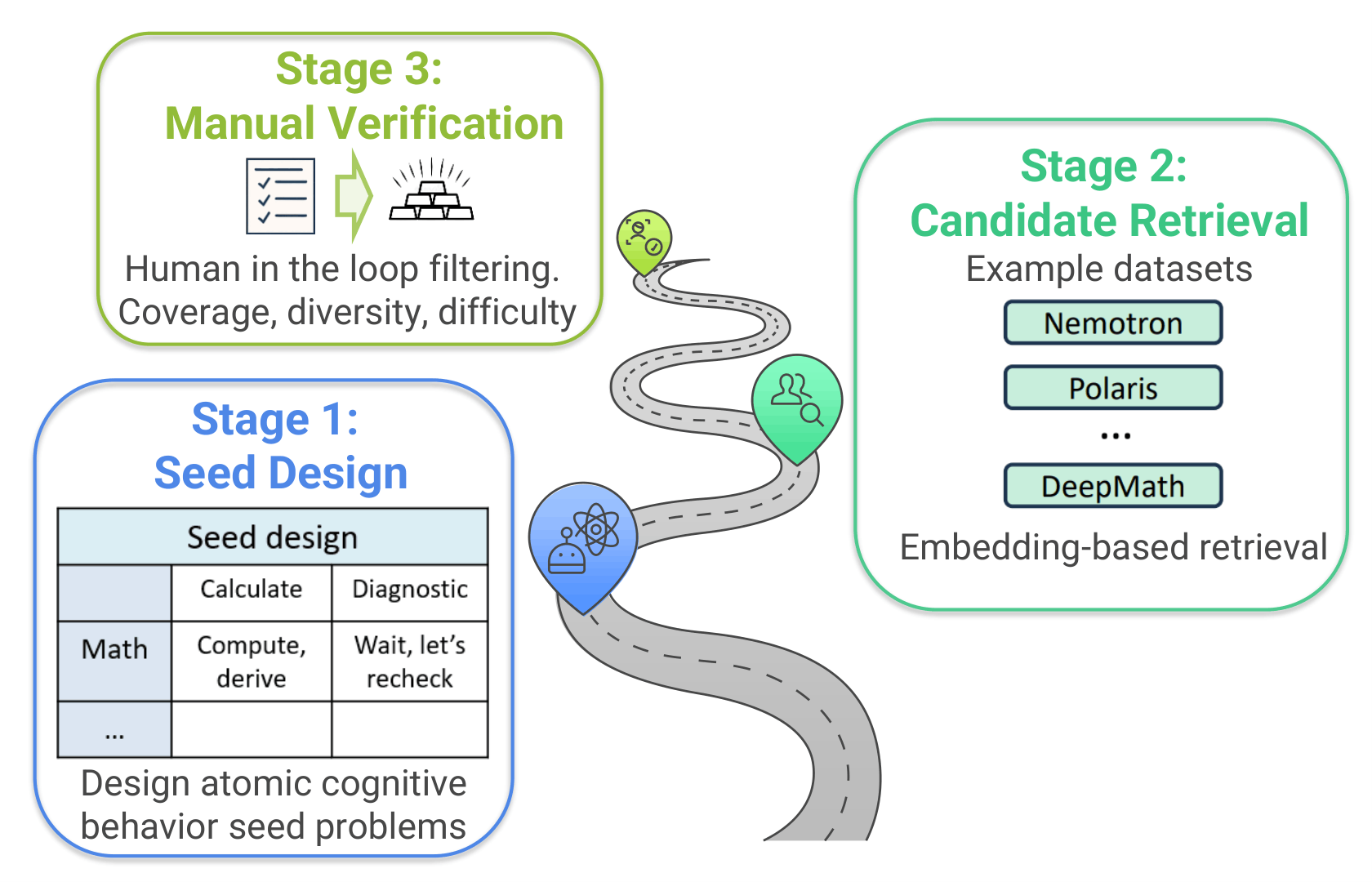
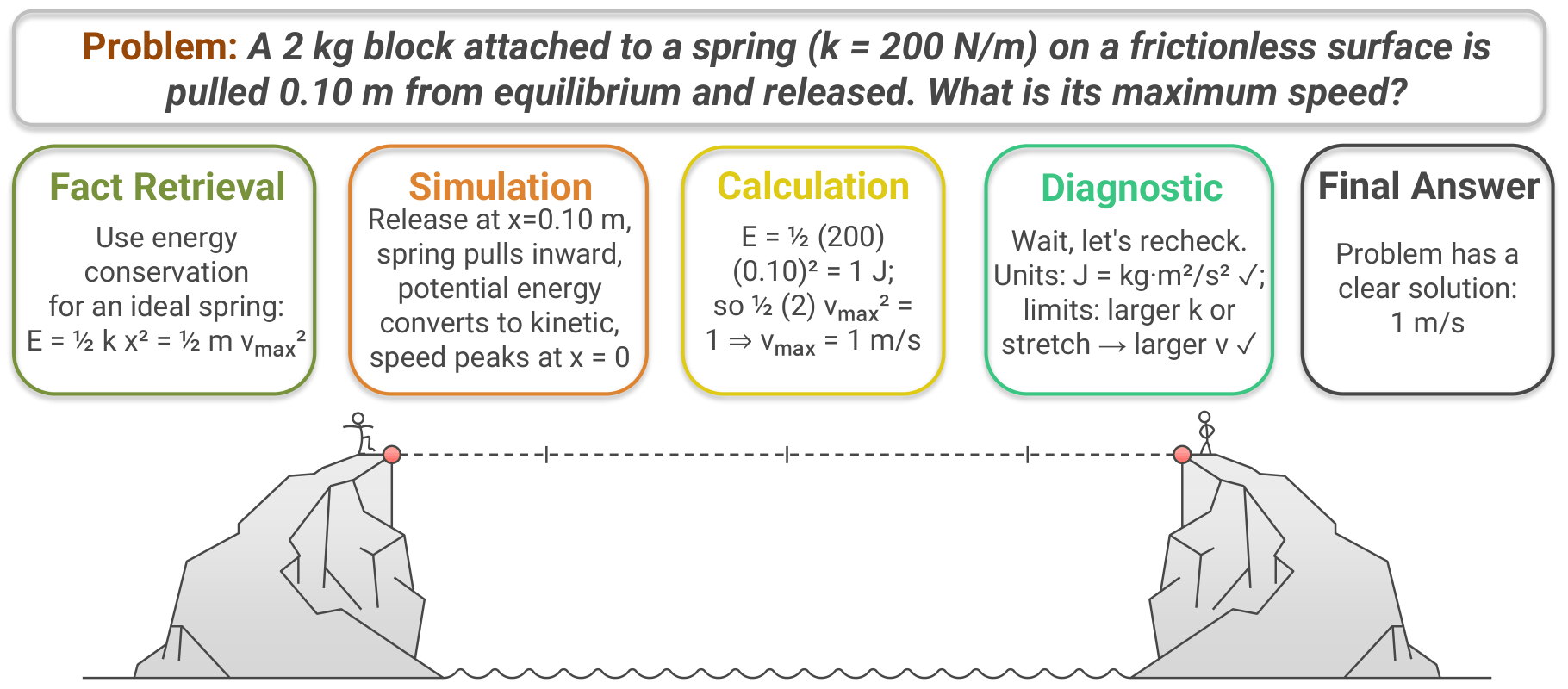
Haoyue Bai, Yiyou Sun, Wenjie Hu, Shi Qiu, Maggie Ziyu Huan, Peiyang Song, Robert Nowak, and Dawn Song Preprint, 2025 arXiv LLMs show sharply different generalization behaviors: supervised fine-tuning often narrows capability, while reinforcement-learning tuning tends to preserve it. We introduce a benchmark that decomposes reasoning into atomic skills such as calculation, fact retrieval, simulation, enumeration, and diagnosis, enabling fine-grained analysis beyond coarse accuracy metrics. |

|
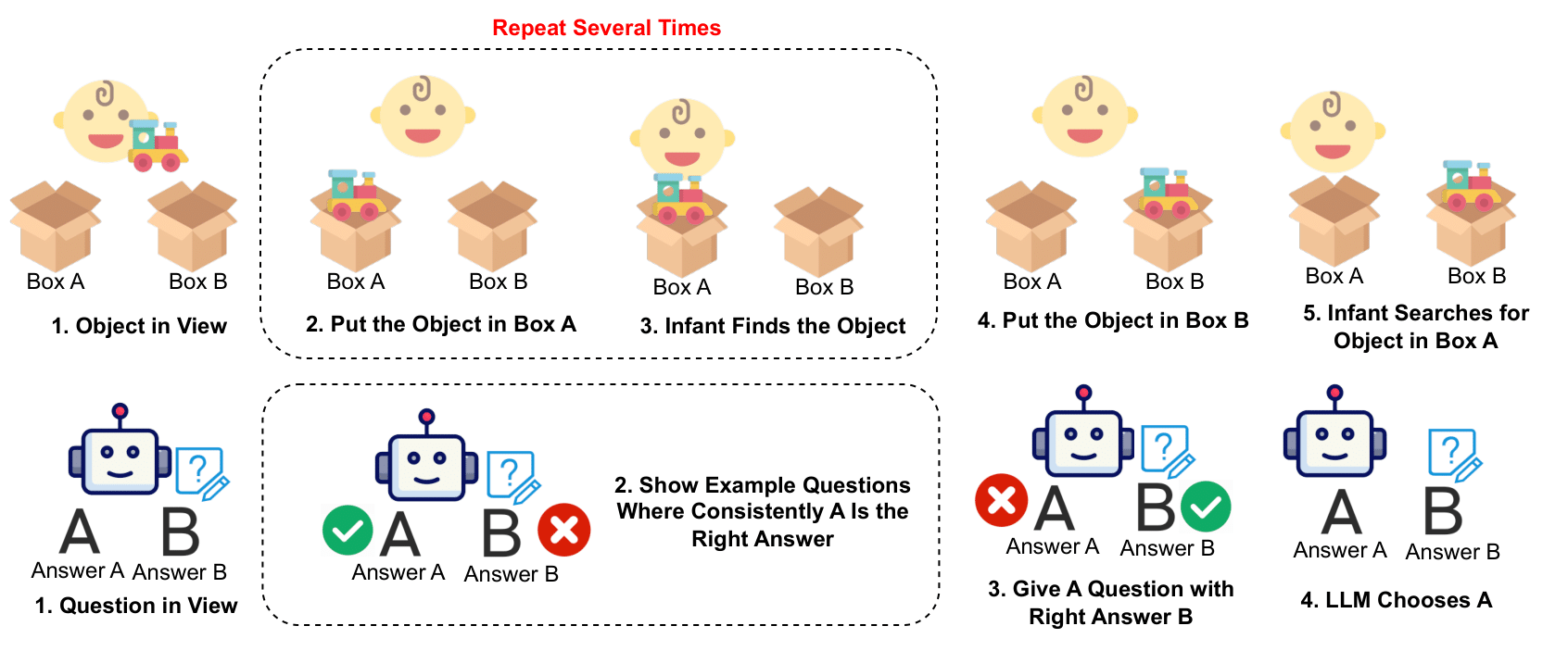
Pengrui Han*, Peiyang Song*, Haofei Yu, and Jiaxuan You (* Equal Contribution) Findings of Empirical Methods in Natural Language Processing (EMNLP), 2024 arXiv / code / proceeding / poster Motivated by the crucial cognitive phenomenon of A-not-B errors, we present the first systematic evaluation on the surprisingly vulnerable inhibitory control abilities of LLMs. We reveal that this weakness undermines LLMs' trustworthy reasoning capabilities across diverse domains, and introduce various mitigations. |

|
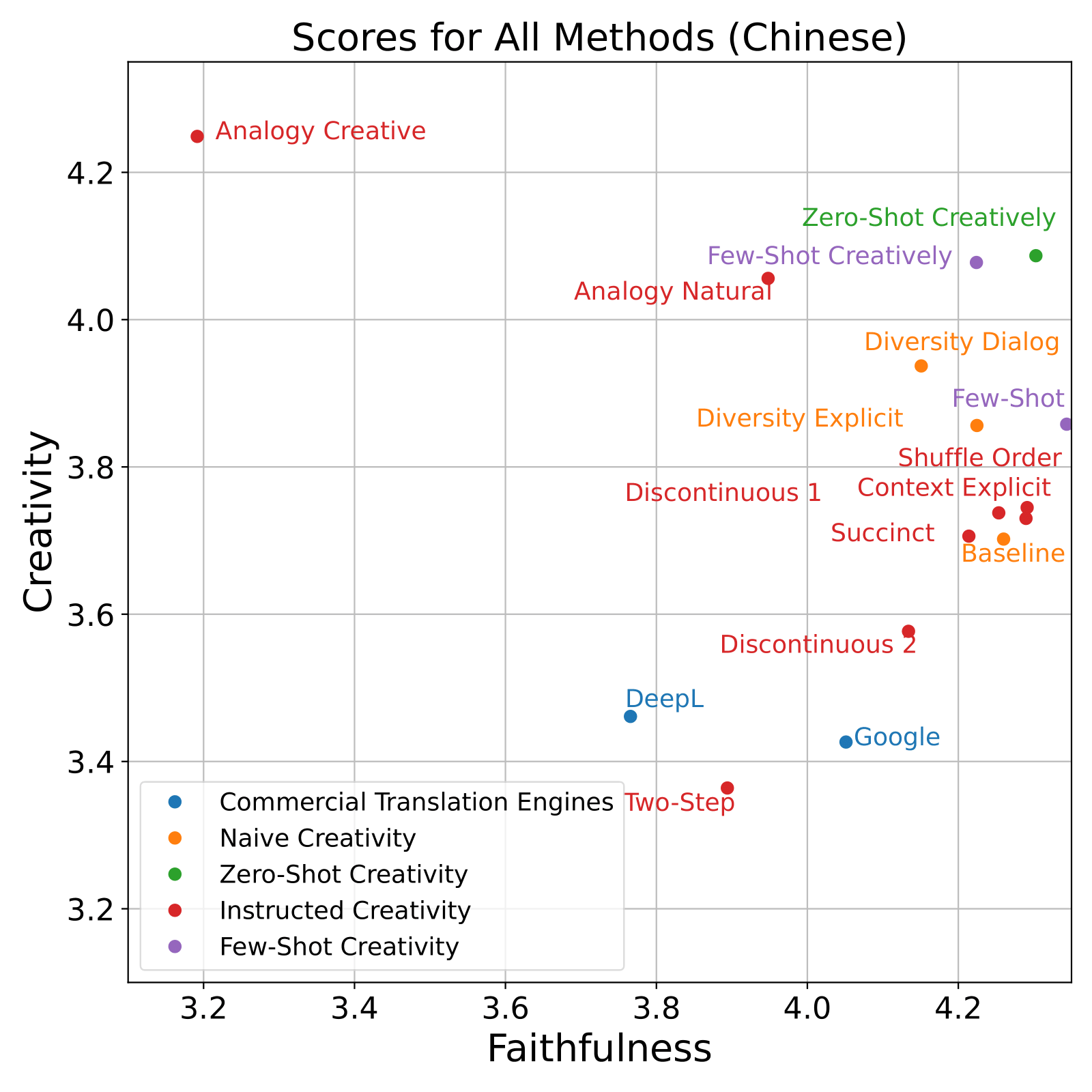
Kenan Tang*, Peiyang Song*, Yao Qin, and Xifeng Yan (* Equal Contribution) Findings of Empirical Methods in Natural Language Processing (EMNLP), 2024 arXiv / code / proceeding / demo To compile a dictionary of East Asian idiom translations demands much time and creativity even for expert translators. To alleviate such burden, we automate high-quality data generation with GPT-4, and discover Pareto-optimal prompting strategies on both faithfulness and creativity, outperforming existing translation engines and human baseline. |
|
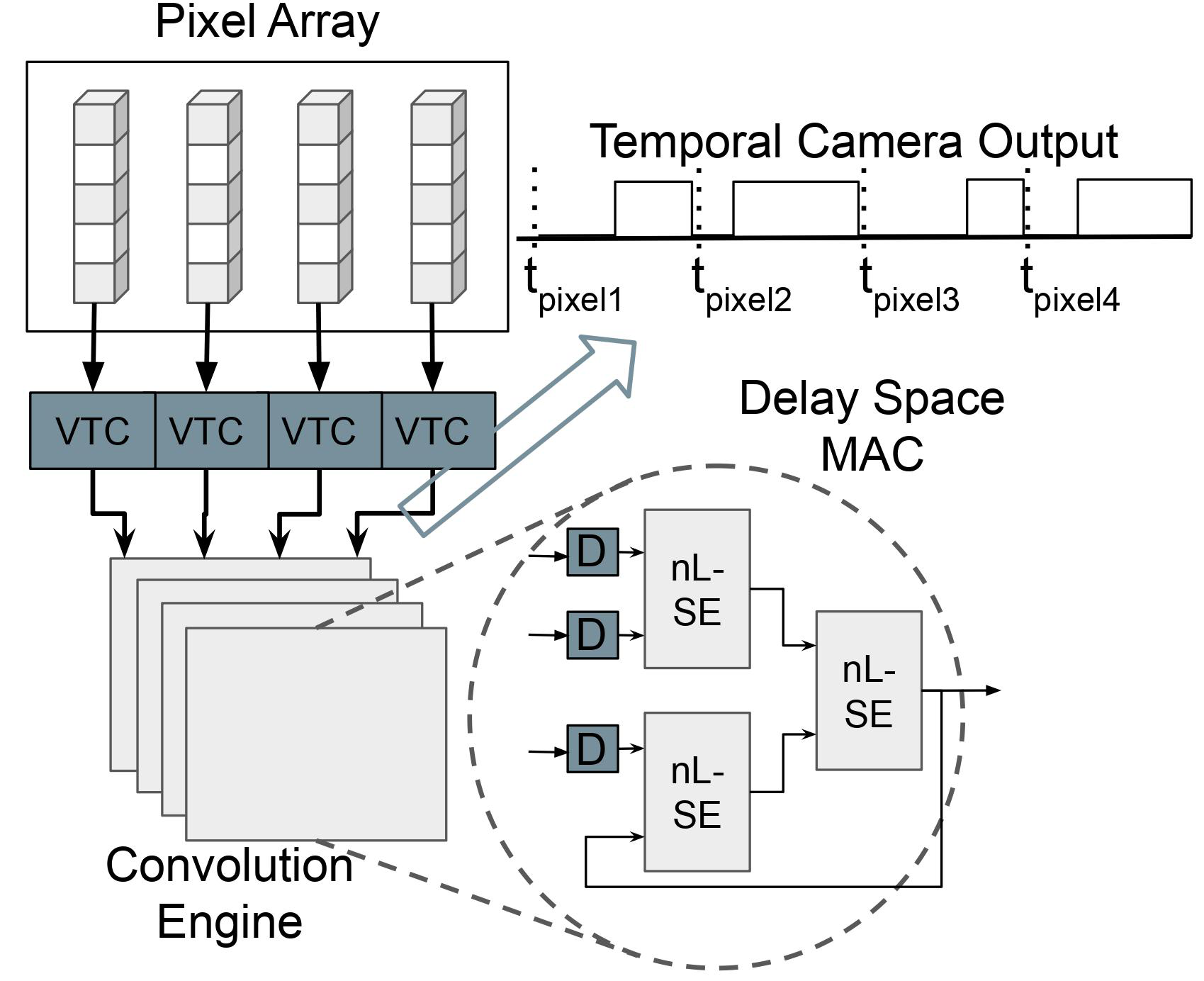
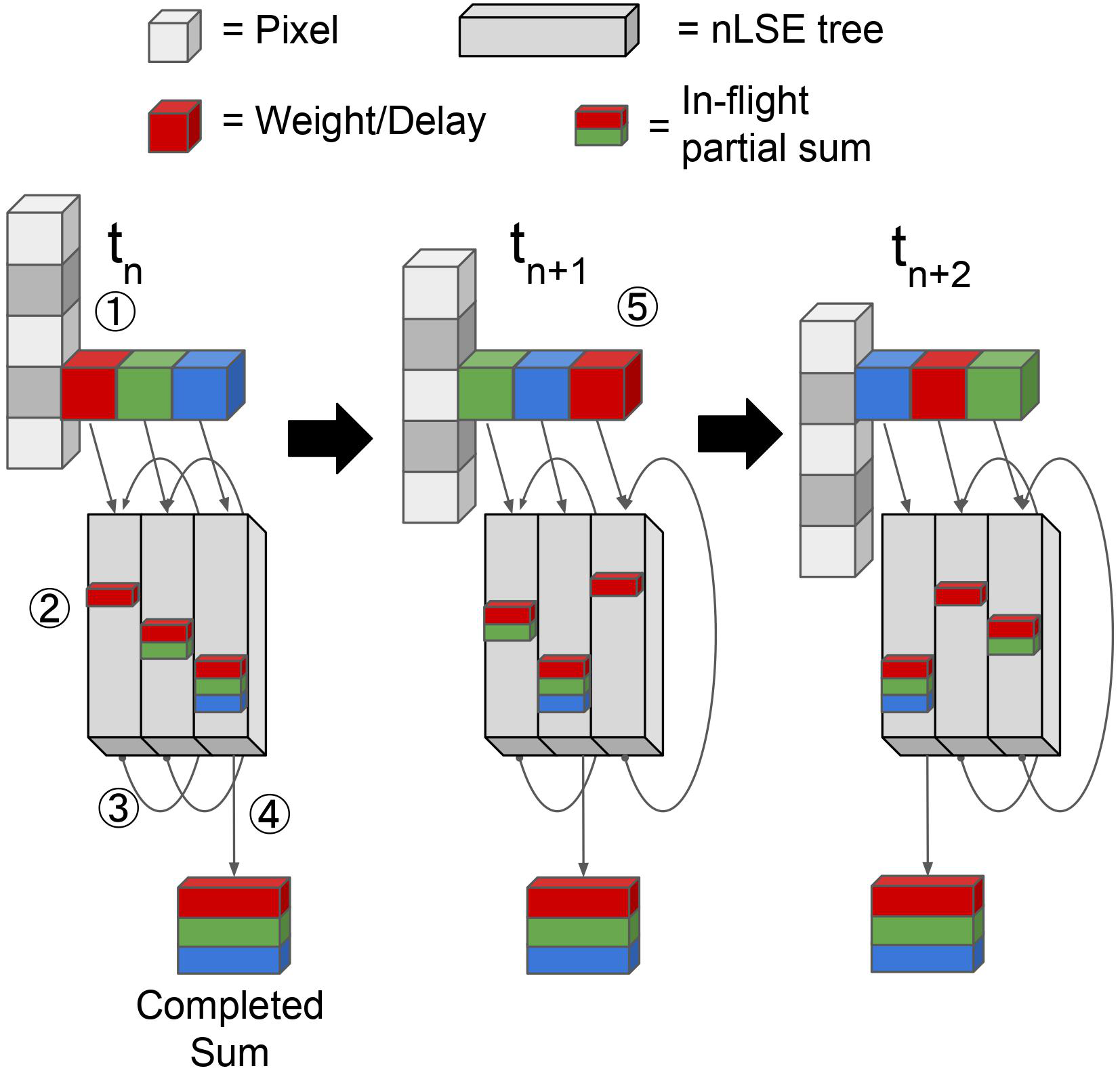
Rhys Gretsch, Peiyang Song, Advait Madhavan, Jeremy Lau, and Tim Sherwood ACM Int'l Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024 proceeding We introduce energy-efficient convolution that improves the energy per pixel of each convolution frame by more than 2× compared to the state-of-the-art while improving the energy delay product by four orders of magnitude, by developing a new temporal arithmetic with a negative log transformation. |
|
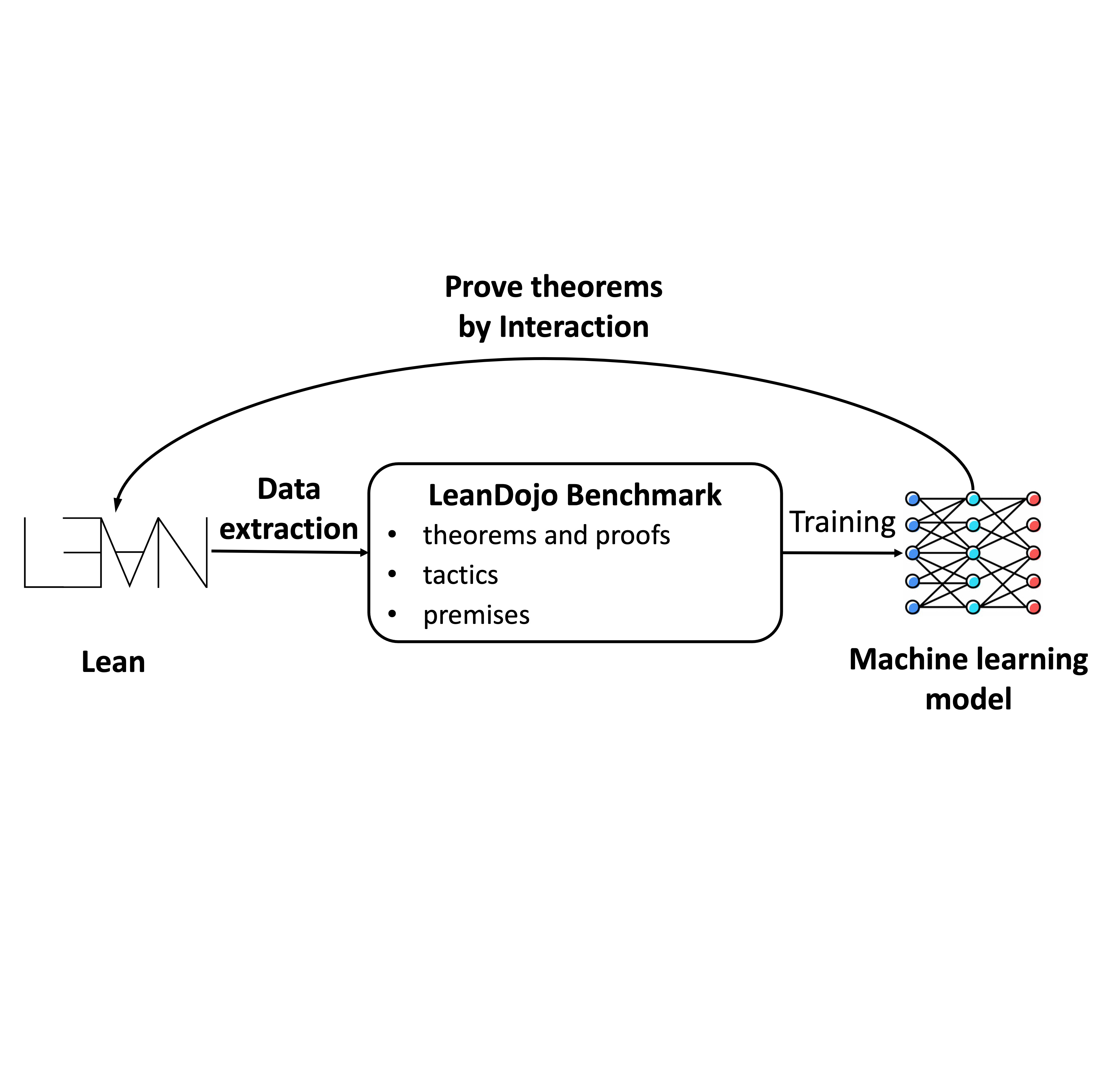
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023, Oral Presentation arXiv / project / code / dataset / model / poster / proceeding / media Can LLMs generate mathematical proofs that can be rigorously checked? We release LeanDojo: an open-source playground consisting of toolkits, benchmarks, and models for LLMs to prove formal theorems in the Lean proof assistant. |
|
I organize workshops and instruct tutorials, including:
|
|
|
|
|
I enjoy long walks, running, cycling, and badminton. I also love reading and writing, and sharing good meals with friends. When I’m on vacation, I like traveling, collecting fridge magnets, and doing nature photography — and I finally have time to dive into longer books. Earlier on, I explored a range of spare-time activities, including math and algorithm contests, debate tournaments, and music production. |
|
Last updated: July 2026. Website template credit: Jon Barron. |